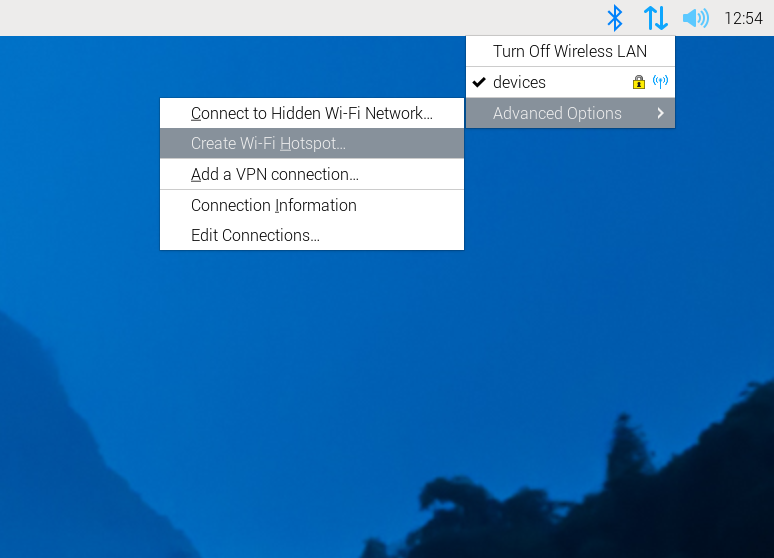
How to Take Screenshots of Menus Using the Raspberry Pi 5
I recently had the inclination and the opportunity to work with a Raspberry Pi 5, and I needed to document the work I was doing.… Read More »How to Take Screenshots of Menus Using the Raspberry Pi 5